AlphaGo出来之后,对它的解读一直不断,而AlphaGo Zero和AlphaZero文章发表后,复现的文章也是层出不穷。写这篇博文的时候,真是感觉诚惶诚恐—不太可能将AlphaZero讲的比知乎上的这篇文章更清晰明了了。作者写的MCTS的讲解纠正了我对UCT算法的好多误解。

MCTS(蒙特卡洛树搜索)
和人类下棋的思路类似,AlphaGo也需要模拟好多次下棋的步骤,探索哪一步是更好的招数。对于下图:
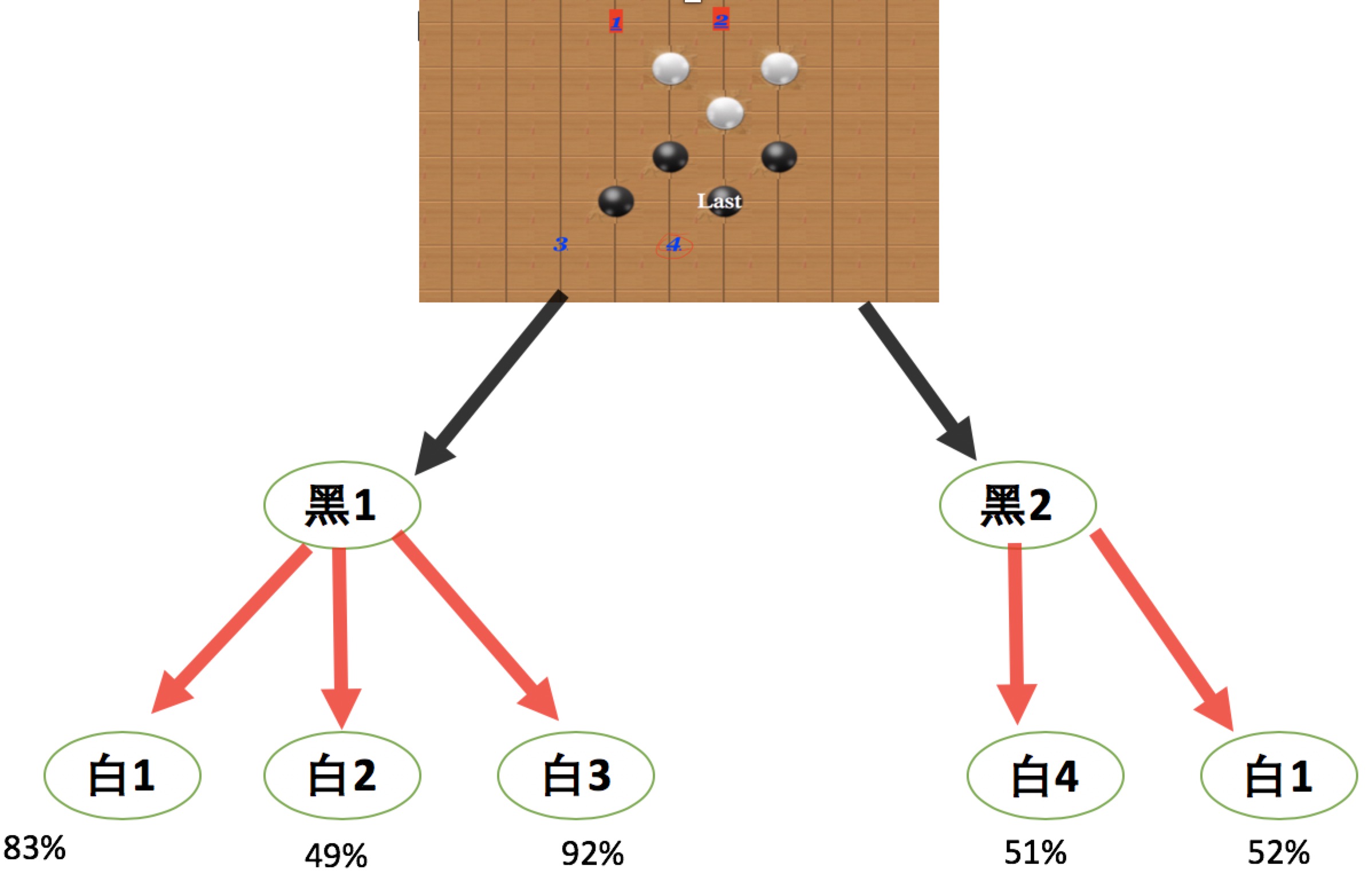 黑棋有黑1, 黑2两个走法;对应黑棋的黑1位置,白棋有白1,白2,白3三个走法(别管图中具体位置了,这是个例子而已);对应黑2位置,白棋有白4,白5两个走法。那么这时候,黑棋应该走哪个呢?假设白棋也走了这五个位置中的某个,我们可以得到黑棋的胜率分别为83%, 49%, 92%和 51%, 52%(胜率如何计算,由价值网络决定,暂且不表)。
黑棋有黑1, 黑2两个走法;对应黑棋的黑1位置,白棋有白1,白2,白3三个走法(别管图中具体位置了,这是个例子而已);对应黑2位置,白棋有白4,白5两个走法。那么这时候,黑棋应该走哪个呢?假设白棋也走了这五个位置中的某个,我们可以得到黑棋的胜率分别为83%, 49%, 92%和 51%, 52%(胜率如何计算,由价值网络决定,暂且不表)。
那么你会如何下呢? 可能你胆子比较大,于是决定下黑1,因为黑1的平均胜率是:(83%+49%+92%)/3=74.67%; 而黑2的平均胜率只有(51%+52%)/2 = 51.5%。 但是,MCTS则走b2,白4的最低胜率51%也高于白2的49%。而如果白棋很聪明,一定会走白2的。所以,MCTS会选择走黑2。MCTS尽量会在轮到对方走的时候,选择对自己最不利的着法来走。
SESB(选择,扩展,模拟,回溯)
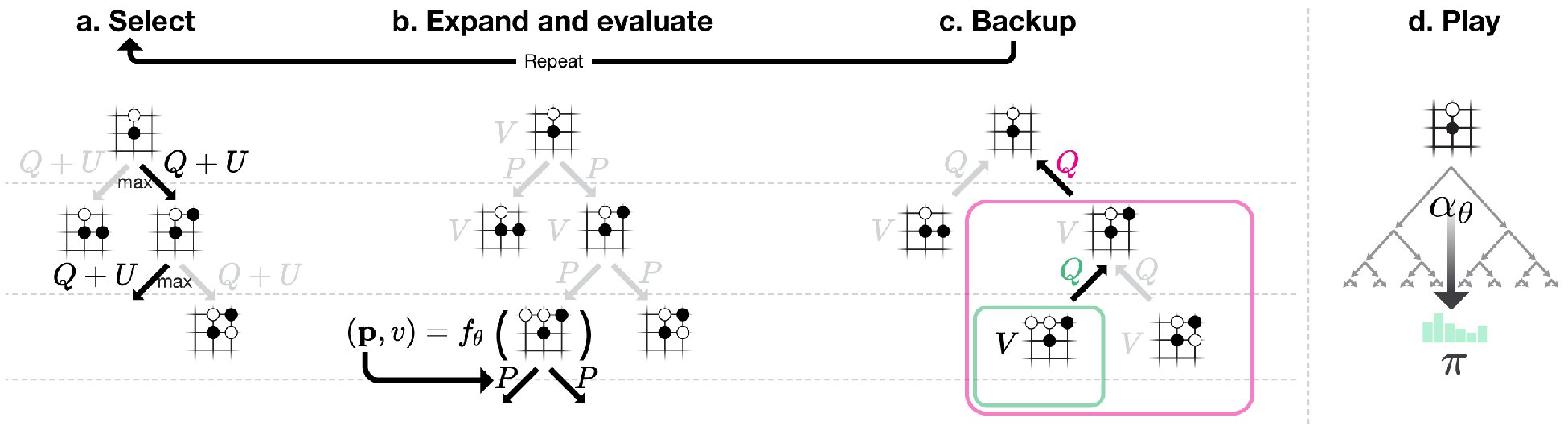
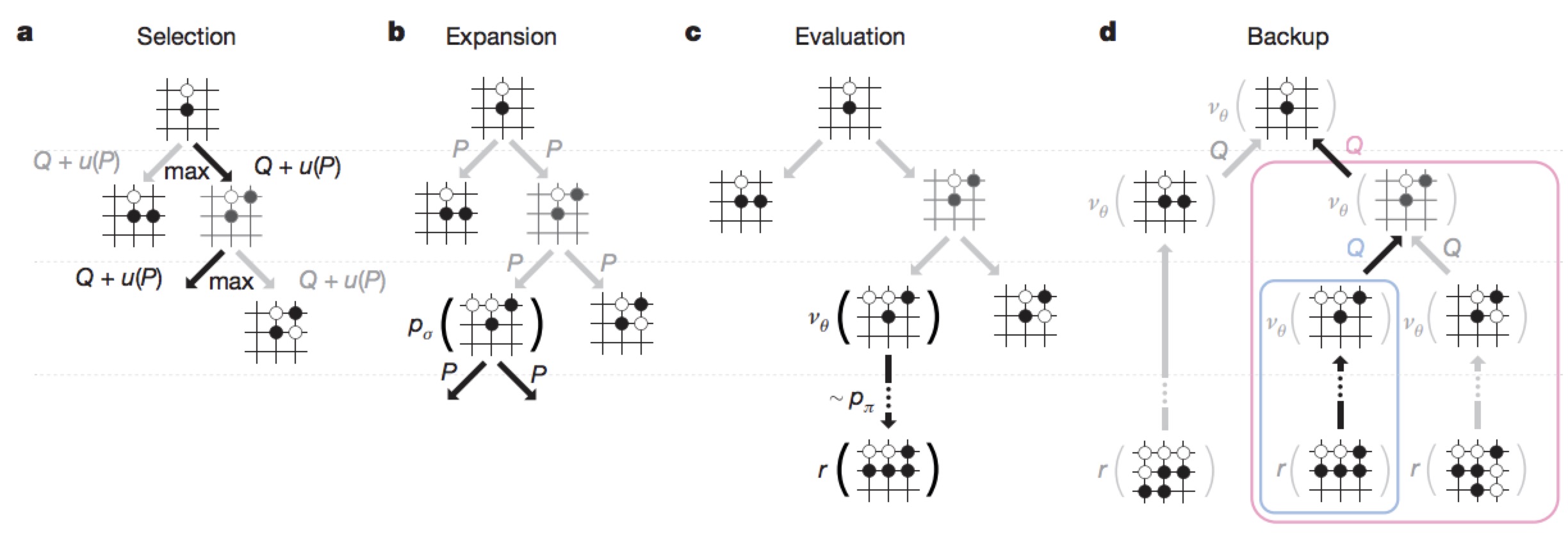
在AlphaGo中,mcts对每一个节点进行1600次类似上图的模拟,以此来决定走子策略。不同与传统纯MCTS的是,AlphaGo并不需要一直把这盘棋下完才能知道输赢,它可以(能?)像上图一样仅搜索两层就知道了哪种走子赢率更大。
策略网络
围棋(五子棋15x15)棋盘为19x19,这样MCTS每一步要需要搜索很广的情况,显然不划算。人类面对这种情况,是凭借直觉(还是计算呢?)确定几个概率大(比如五子棋,直接就不考虑边和角了)的点,然后在这几个点上再深度模拟(多走几步)。AlphaGo中的策略网络,就是充当这种直觉的:它通过输入19x19的图像,直接输出361个点的概率,然后搜索概率较大的点就可以了。
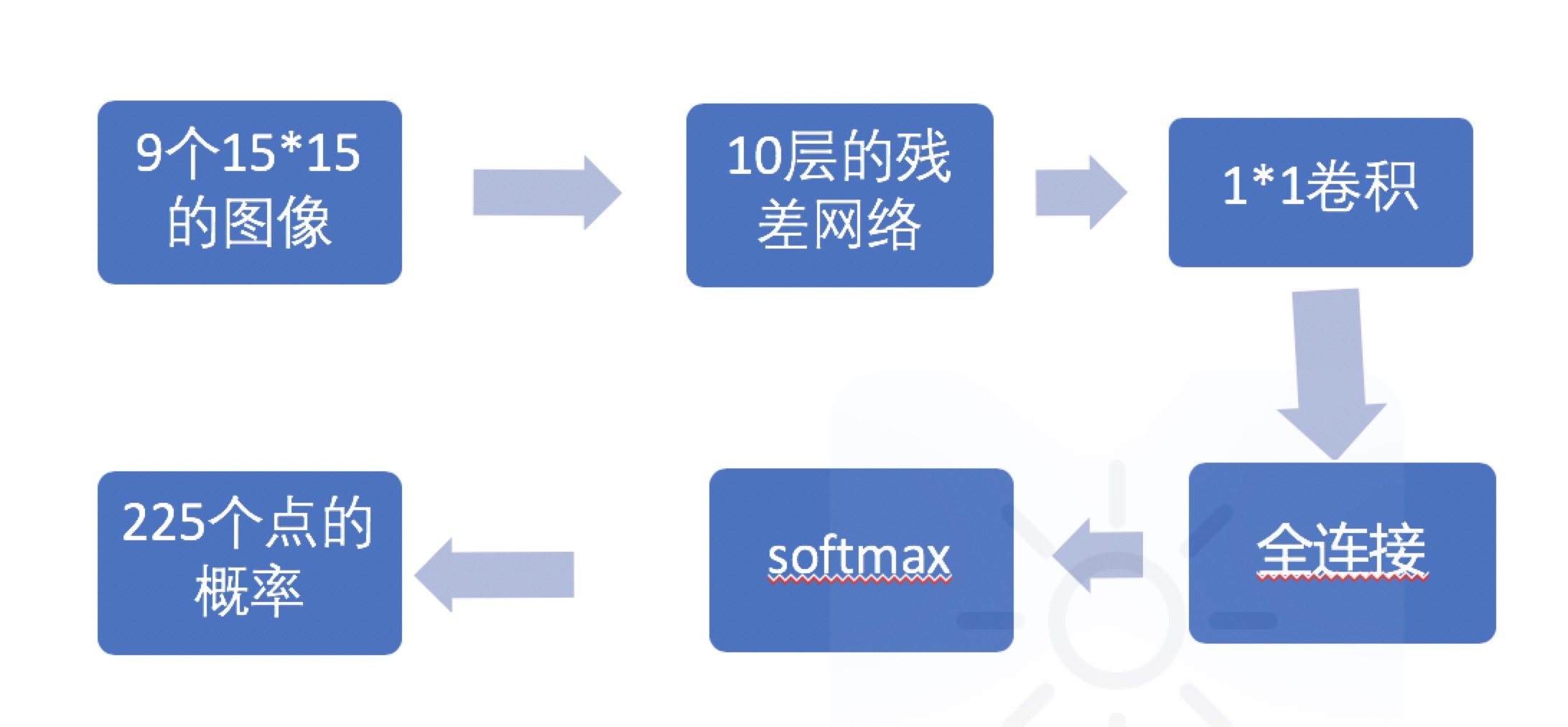
在AlphaPig中,我们将最近下的9个位置(黑,白…当前是否黑)作为特征输入卷积网络,然后得到225个行棋概率。
价值网络
在AlphaZero中,价值网络开始和策略网络使用同一个卷积网络(不清楚AlphaGo中为什么一开始是两个),为40层的残差网络。而价值网络输出的,确是一个介于0~1(1是当前player赢了,0是输了)之间的小数。这里我们使用10层的残差,当然,你也可以试一试其他的网络结构(实际上,5层的效果已经很好了)。
不同与AlphaZero的,我在这里并不打算一开始就让它自对弈:训练起来太慢了。我使用了网络上佚名人士提供的5581局人类五子棋比赛棋谱来预训练价值与策略网络,之后再让它开始的自对弈,训练速度有所加快。
初期不能明白的是,假设白棋一直下的很好,每一牌面(一次对弈有很多个牌面)都是神来之笔,而黑棋下的都很臭!最后黑棋一个不小心赢了。那么依然是白棋每个牌面为0,黑棋每个牌面为1吗?是的! 虽然违反直觉,但是要相信,下得棋盘多了,最后还是会收敛的,不会每次的对弈都是这样(每次对弈大部分牌面都还是赢者的下法棋高一着)。
tips
训练时候,c_puct(控制MCTS的搜索广度)可以稍微设置大一些,如果训练的网络不错,可以试着把c_put设置的稍微小一些;自对弈的时候,dirichlet_noise根据自己的棋盘大小,可以尝试设置的稍微大一些,这样可以防止每一句的自对弈都是一个样子,我刚开始训练的时候,每次的博弈都是一样的局面,毫无新意,尝试了引入开局库(不要引入必胜开局库),情况稍微好了一些。
可以尝试在evaluate目录下,自己和训练的AI对弈,来增加数据,或者搭建局域网对弈,收集更多人机博弈的棋谱。

TODO:
对弈棋局棋谱保存,fix棋谱边缘估值(策略)网络智障。
更多进展,请follow AlphaPig。
特别致谢
-
源工程请移步junxiaosong/AlphaZero_Gomoku ,特别感谢大V的很多issue和指导。
- 特别感谢格灵深瞳提供的很多训练帮助(课程与训练资源上提供了很大支持),没有格灵深瞳的这些帮助,训练起来毫无头绪。
-
感谢Uloud 提供的P40 AI-train服务,1256小时/实例的训练,验证了不少想法。而且最后还免单了,中间没少打扰技术支持。特别感谢他们。